Practical Operational Meteorology Tools in 2025: How is it changing in the AI era?
There has been a lot of healthy conversation and debate over the past 2 years on the changing landscape in meteorology now that AI is front and center. I’ve been asking myself what changes, if any, do I need to consider in my approach to forecasting in an operational setting? Will the changes really improve decision-making for end users? Is this any different than what we’ve already been doing? To what extent should I participate in this machine learning / AI “frenzy”?
Many of my colleagues with whom I’ve had conversations have differing views on the practical implications of these technologies. Some have expressed considerable skepticism and the fact that AI may not be a replacement for the physical models. In essence, it’s “one more thing I have to look at” when techniques that have been available for years, indeed decades, work well. There are those who are fully embracing the advancements, acknowledging the benefits and pitfalls. And, as you might imagine, there is a large continuum in the middle with all kinds of nuance on which I won’t elaborate here.
My view is evolving and I expect it will continue to do so. Knowing how artificial intelligence will precisely impact operational meteorology may be harder than making a daily weather forecast all by itself. At the considerable risk of oversimplication, I lean strongly toward embracing these changes, recognizing the traditional physical models have their strengths, too. Throwing the baby out with the bathwater is unwise.
Over the past two years, I’ve had the good fortune of stumbling upon some exceptional courses on Coursera,
including the Applied Data Science with Python Specialization by the University of Michigan,
and Machine Learning Specialization by Andrew Ng and DeepLearning.AI. I’ve left those links here for your convenience should you have interest, but there are many others. Last week, I was re-reading Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow by Aurélien Géron. In full disclosure, I have not read the entire book and have read parts of it as reference, reinforcement, and a refresher to my coursework – but the first two chapters reminded me of important things:
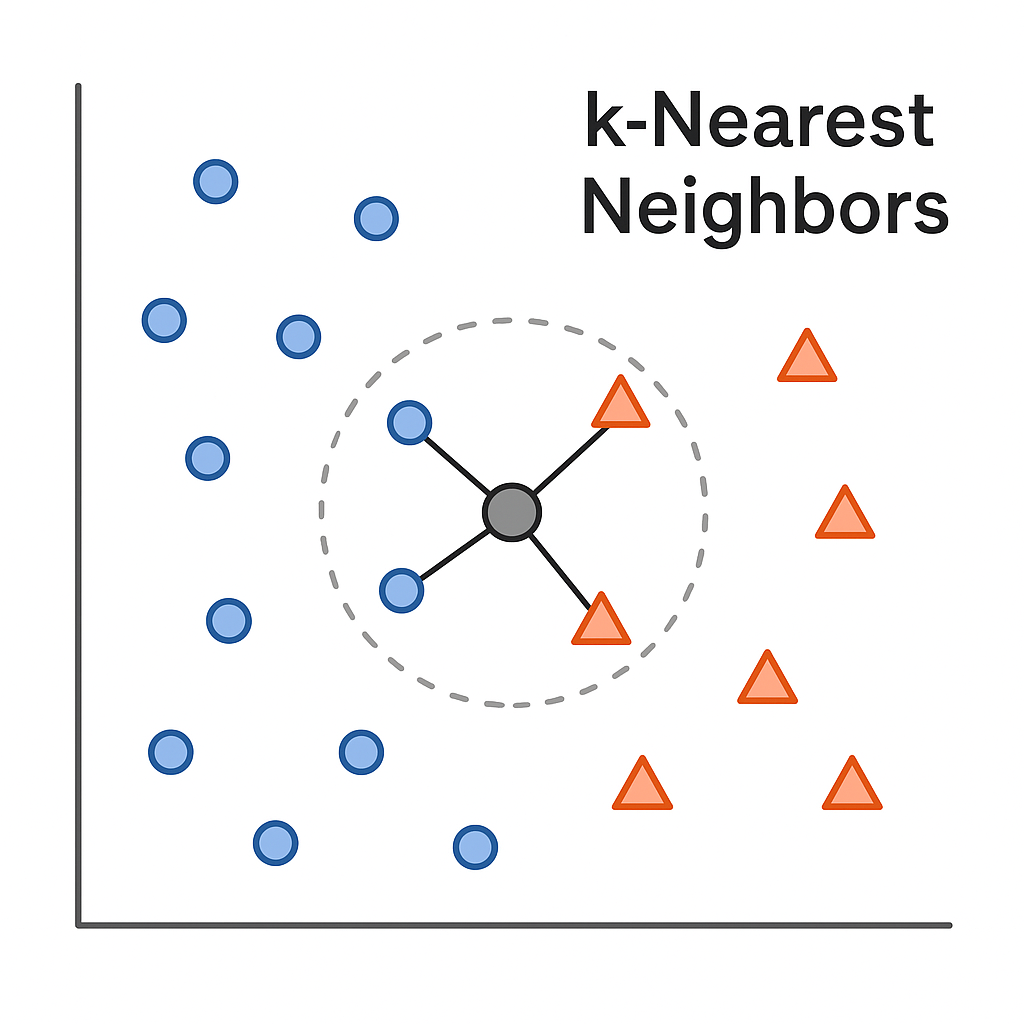
The field has been doing a lot of this stuff for decades: Instance-based learning is a technique that, in effect, finds other similar cases to examples you've provided to an algorithm. Analog forecasting is one such case (i.e., what months or years in the past have exhibited similar patterns that produced similar outcomes). K-Nearest Neighbors, or KNN, is a simple yet powerful instance-based learning method that classifies new examples by comparing them to known ones.
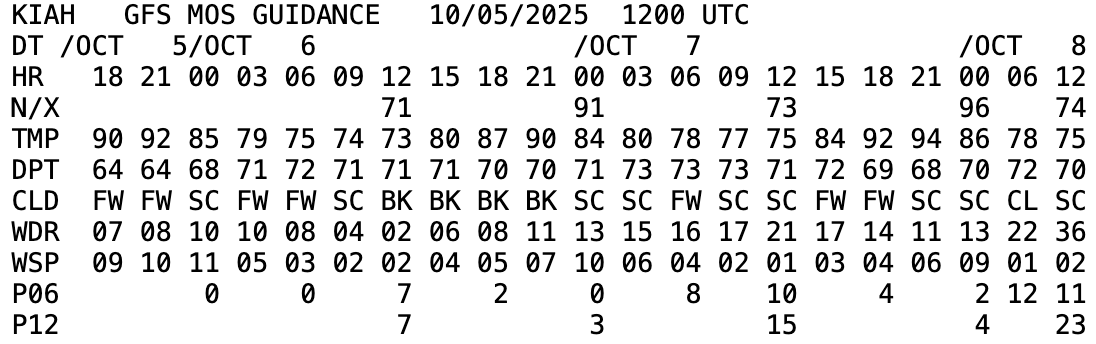
k-nearest NeighborsModel-based learning has also been used for decades in the field. Anyone still use the MOS (Model Output Statistics)? The MOS uses linear regression, with historical inputs to, in effect, nudge the raw model output toward the actual surface observations that have been observed under similar past conditions.
MOS Output for Houston showing forecast.
It's possible for those to learn what some of these techniques are doing without "hard" math: I'm not necessarily advocating that one should not pursue advanced math, like linear algebra, which are the basis for these algorithms. That's up to each person and their interests. After all, I've only dabbled a very small amount in it myself. What I'm saying is that, even without it, one can achieve a far better understanding of what these algorithms are doing. There's no doubt in my mind that the operational meteorologist can be in a position to ask the right questions when evaluating new models and techniques -- or maybe even propose concrete ideas of their own!
I’m looking forward to adding more in this space for those who might be inspired to see practical applications.